[JAVA] 자바 Runtime Data Area 분석
** 개인 학습을 위해 작성된 글이며 모든 정보는 오류가 있을 수 있습니다.
자바 Runtime Data Area 에 대해 알아보기전 간단하게 자바 프로그램의 실행과정에 대해 간단하게 알아보겠습니다.
개발자가 작성한 자바 코드를 자바 컴파일러가 바이트 코드로 변환시켜줍니다. 로딩된 클래스들은 Execution Engine을 통해 해석됩니다. 이후 해석된 바이트코드는 Runtime Data Area 에 배치돼 실질적인 수행이 이루어집니다.
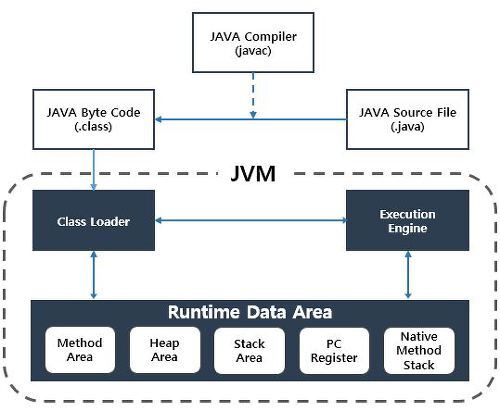
Runtime Data Area의 구조는 그림과 같이 5가지 영역으로 나뉩니다.
5가지 영역중 Method Area 와 Heap Area 는 스레드들이 공유하는 영역이고 Stack Area, PC Register, Native Method Stack 은 개별 스레드마다 하나씩 생성되는 메모리 영역입니다.
그럼 Method Area 부터 차례대로 특징에 대해 살펴보겠습니다.
1. Method Area
JVM 당 하나만 실행되며 모든 스레드들이 공유하는 영역.
클래스로더에 의해 로드된 클래스정보, 인터페이스, 메소드, 필드, Static 변수 등을 보관한다.
JVM 구동 시작 시 생성되며 종료시까지 유지된다.
2. Heap Area
Method Area 와 같이 JVM 당 하나만 실행되며 모든 스레드들이 공유한다.
자바의 new 연산으로 생성한 인스턴스, 배열등이 저장된다.
자바의 경우 JVM의 가비지 컬렉터가 Heap 영역에서 더이상 참조되지않는 메모리 정보를 얻어온 뒤 알아서 제거해주기 때문에 C, C++과 다르게 인스턴스를 생성한 이후 free(), delete 연산을 해줄 필요가 없다.
3. Stack Area
각 스레드마다 별도의 스택을 가진다.
지역변수, 매개변수 등을 저장한다.
메서드 호출 시 스택 프레임이 증가하며 반환 시 프레임 자동 소멸된다.
4. PC register
각 스레드마다 별도의 문맥을 가지므로 스레드마다 개별 PC register를 가진다.
일반 CPU 처럼 Program Counter를 가지며 같은 역할 수행한다.
5. Native Method Stack
스레드마다 별도의 Native method Stack 을 가진다
Java 외의 언어로 작성된 네이티브 코드들을 위한 stack 이다.
** 다음 공부할것
Garbage Collection 동작과정 알아보기